DS e IA: Primos Lejanos

La Intro
Si me lees recurrentemente, sabes que me gusta preparar el terreno, contar un poco de historia, mi versión, un “había una vez”. No excepciones por hoy, un poco de historia viva de la inteligencia artificial generativa desde un ex científico de datos. Sí, dije ex.
Cuando todo partió desde ChatGPT 3.0 (más o menos) se acuñó el cargo Prompt Engineering Engineer y la verdad fue todo un meme.
¿Su definición? Usar prompts y estrategias para formatear una salida o procurar que esa salida fuera lo más consistente posible. ¿Para qué? Para crear un sistema que pudiese realizar una o varias tareas secuenciales o en paralelo para solucionar un problema. Por aquel tiempo, en promedio, se hablaba mucho de:
- System Prompt y user prompt.
- Zero-shot y few-shots.
- Chain of thought.
- Defensive prompt-engineering. …etc.
¿Y el desafío de eso era…? No lo mires en menos; algo tenía y sigue teniendo.
Lo que recuerdo era que pasabas harto tiempo buscando e iterando formas/estrategias para que el output de un LLM fuese consistente o lo más determinístico posible. Es loco, pero eso duró poco, diría que ¿6 meses aproximadamente?.
Luego de eso, todo siguió avanzando y apareció el cargo, que probablemente ya existía, pero la evolución o la respuesta de la industria (por lo menos en Chile) fue crear un cargo llamado IA Engineer.
Mi pregunta es, ¿de dónde salieron los AI Engineer? A lo que me refiero, ¿quiénes son esas personas?
Bueno, para mí los IA Engineers son los Data Scientist más intrusos/inquietos que vieron en GenAI un potencial “algo”.
¿Viste que no era tanto contexto?
En este post hablo sobre algunas reflexiones que me quedan luego de haber transicionado de la ciencia de datos a GenAI, mi rol como líder con mi equipo en esa transición, las diferencias entre un Data Scientist y un AI Engineer, los skills nuevos y necesarios que se requieren, lo que hemos aprendido, lo que nos falta y seguimos trabajando.
¡Uff! ¿Contenido de calidad, verdad? Hoy en Ideas en Papel, en su edición número 8, tenemos lo que no se compra en la farmacia de la esquina y lo que no encontrarás en Linkedin, un caso real, problemas reales y cosas que te aportan. (¡Auch!)
Listo, prepara la mente y, como siempre, deja las distracciones de lado y concéntrate.
Hay diferencias
¿Hay alguna diferencia entre un Data Scientist y un AI (GenAI) Engineer? ¿Es necesario hacer la distinción o es otra sofisticación innecesaria? Al hueso, como siempre, la distinción entre Data Scientist y AI Engineer creo que es 100% necesaria y está totalmente justificada. Son perfiles distintos, con skills distintos, y si eres líder de algún equipo o tienes el desafío de formar un equipo de IA, los equipos y perfiles que se relacionan a los AI Engineers deben ser distintos también.
La diferencia principal es en la tarea que resuelven. El Data Scientist realiza un modelo de ML (Machine Learning); el AI Engineer debe crear una solución integral que es bastante parecida a un software o app. Y de hecho, una vez que resuelven la tarea o problema, con quien se relacionan también es diferente; el Data Scientist se relaciona con un MLOps al terminar su desarrollo y un AI Engineer podría relacionarse con un DevOps, Ingeniero Cloud, Arquitecto o LLMOps. (he escuchado esto en algunos lugares)
¿Se entendió? No. Bueno, veámoslo con un ejemplo real.
Si eres científico de datos, el proceso estándar es más o menos así:
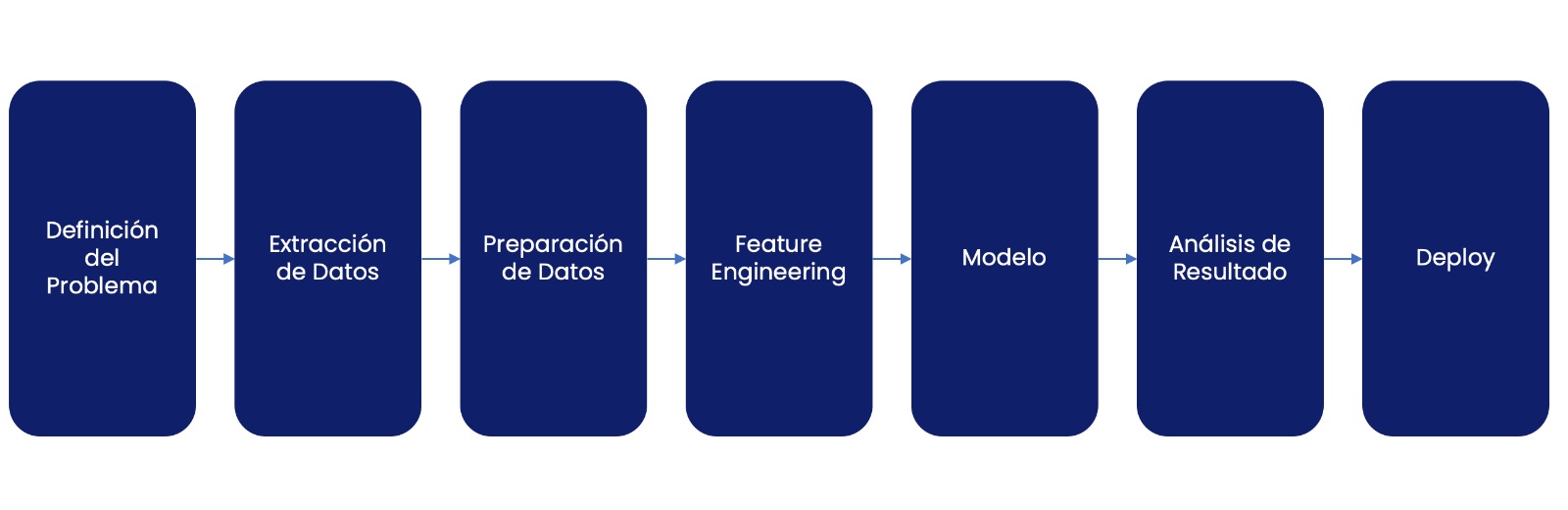
En AI Engineering el esquema es distinto y los modelos de lenguaje son open-ended, es decir, la tarea a resolver es amplia, multipropósito y, por lo tanto, difícil de generar un esquema genérico para el proceso, pero lo mostraré con un ejemplo real (no-chatbot, no más chatbots por favor!) de una solución interna con GenAI que desarrollamos para crear contratos para abogados utilizando GenAI.
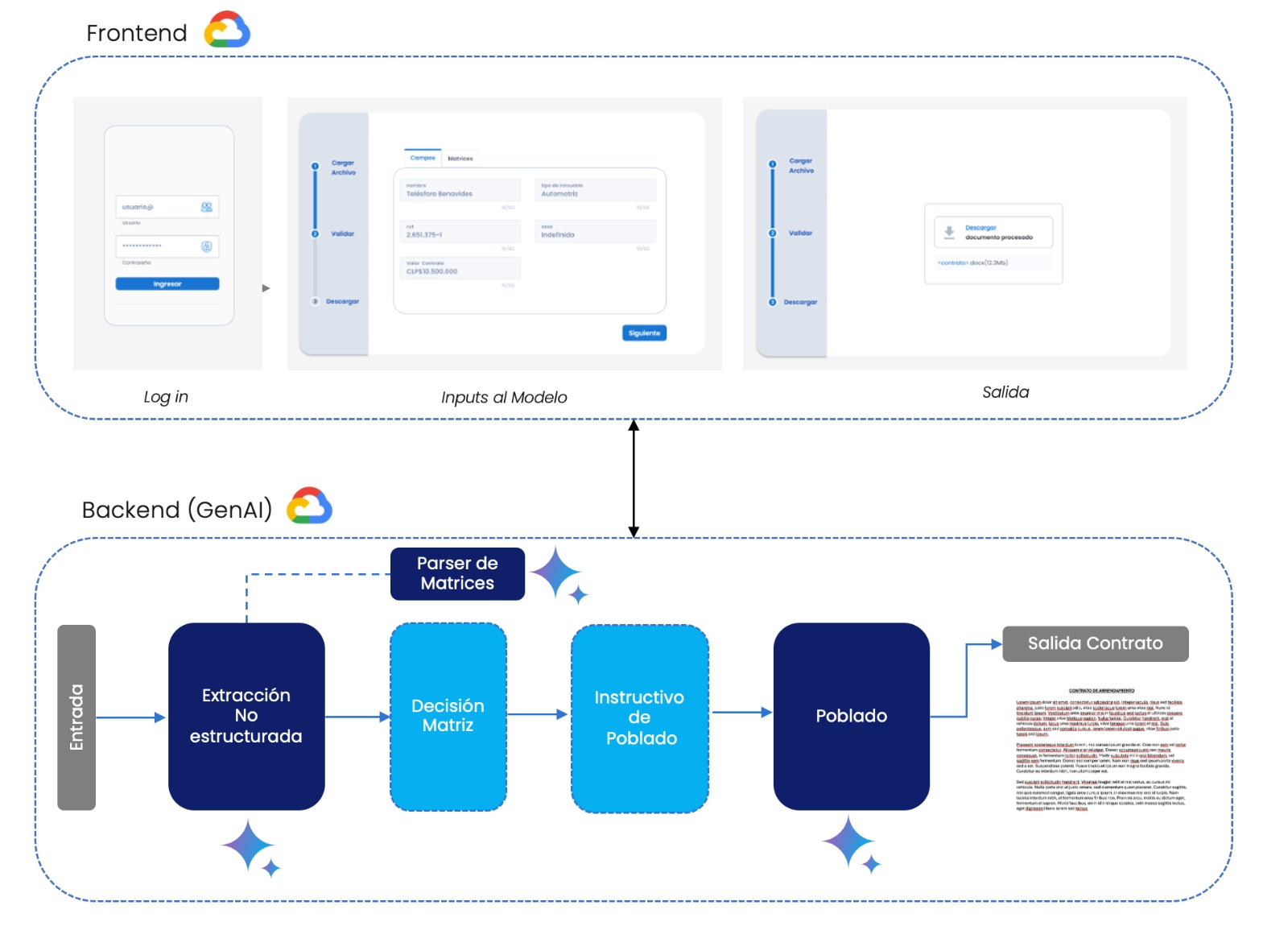
Los esquemas son ¿abismalmente distintos o no? Ni mejor ni peor, solamente distintos. Para este caso de uso, los usuarios tienen que cargar un DOCX de input (no puedo contarte qué tiene ese DOCX, pero son antecedentes) y a partir de eso se genera un contrato utilizando Inteligencia Artificial, dado ese escenario, tuvimos que construir:
- Un Front
- Autenticación mediante un login de acceso.
- Deploy de esta aplicación dentro de una URL interna.
- Limitar el peso de los archivos cargados.
- Permitir solo algunos tipos de archivos de entrada.
- Monitorear el uso del aplicativo, manejo de errores, etc.
Este listado puede ser mucho más extenso (y lo es), pero lo que quiero transmitir es que desde la ciencia de datos estábamos (o estamos) bastante más lejos de estas preocupaciones.
En resumen, hay diferencias.
La definición del rol
Bueno, ¿me la juego entonces con una definición? Voy.
Para mí, un AI Engineer es una persona que desarrolla y utiliza las herramientas de Inteligencia Artificial tanto open source como pagadas, para solucionar un problema específico. Listo.
Ahora, esa solución está mucho más orientada a un desarrollo tradicional de software que la estructuración de problema mediante la ciencia de datos.
Nuestra transición
En mi trabajo actual (en un banco) me ha tocado liderar el cambio de científico de datos a AI Engineers y la verdad ha sido un camino gigante. Con 3 desarrollos de IA en el cuerpo, creo que puedo hablar con algo de propiedad respecto de las cosas que hemos tenido que aprender. Quizás tú que estás leyendo las puedas tomar como aprendizaje, así que comencemos.
Lo díficil
Antes de esto, si me sigues, sabes que me gusta hacerme preguntas; aquí va otra: ¿Qué es lo difícil de esto? ¿De la Ingeniería en IA?
Fácil. Nosotros no somos desarrolladores de formación; por lo tanto, por definición no sabemos hacer una API, no estamos acostumbrados a crear features en una app, preocuparnos de dónde y cómo se deploya una app, cómo podemos ir incorporando los nuevos features y que esas mejoras sean reflejas hacia los usuarios, etc.
Esto para un data scientist es un cambio radical y obliga a cambiarte completamente de disfraz; lo único que queda es que sabes python y tienes que adaptarte y aprender. ¿Lo bueno? Somos ingenieros, resolvemos problemas y creamos cosas, por lo tanto, podemos movernos.
¿Estimulante? Claramente que sí, estamos creando algo real, un producto que tiene vida.
Nuestros Aprendizajes
Mi aprendizaje personal ha sido mediante 3 pilares:
- Estudiar: De manera autodidacta me gusta leer libros referentes a IA Generativa, cómo llevar soluciones a producción, leer documentaciones de los frames más conocidos, videos, internet y GPT, Gemini, etc.
- Haciendo: Lo fundamental es hacer cosas, probar, crear algo. Tú también puedes hacerlo, solo necesitas creatividad. En mi caso tengo la suerte de que en mi rol se nos pide crear casos de uso y eso nos obliga a crear cosas para solucionar problemas.
- Vivir el presente: En los mismos problemas del día a día, debatir ideas con el equipo, imaginarse lo que viene, pensar en cómo se puede mejorar, son aprendizajes sumamente valiosos y que no tienen comparación con los puntos anteriores.
Es así como no vino una consultora, no pagamos a un equipo de acompañamiento. Solamente nos lanzamos al vacío y hemos ido aprendiendo poco a poco. Dado este preámbulo, te cuento los nuevos skills que hemos adquirido (y seguimos mejorando); esto te puede servir para partir, estudiar y, si lideras un equipo, quizás puedas empezar a moverte o entender lo que significa técnicamente.
Partamos.
-
Github: En ciencia de datos he visto poco el uso de Github para colaborar, lo he visto más como repositorio centralizado. Veo que es díficil colaborar cuando construyes un modelo tradicional, en GenAI esto es al revés. Hemos tenido que adoptar Github como un must para colaborar con varias personas a la vez.
-
Docker: Casi que el estándar es Docker para “paquetizar” tu solución. En Docker lo que haces es empaquetar tu desarrollo completo con todas sus carpetas/módulos, features, requerimientos de librerías, versiones y con su respectiva imagen de Python de referencia. Docker, otro must. Si quieres practicar, bájate Docker, “apifica” tu solución de GenAI con FastAPI y lanza tu API desde Docker y hazle requests desde Docker y no desde tu Python local. Wen’ ejercicio.
-
FastAPI: Hoy en día, todo es una API (¿o no?) y nuestras soluciones también lo son o deben serlo. Para ello, FastAPI nos ha hecho la vida más fácil para comunicar backend con frontend.
-
Devops: En nuestra empresa Devops está centralizado, es decir, nosotros como equipo no podemos crear pipelines de despliegue, testeo o integración. Ese hecho no quita que hayamos entendido el cómo Devops nos puede o tiene que ayudar para el producto que estamos desarrollando/construyendo. Devops es el área que se encarga de traspasar nuestro desarrollo por un pipeline de despliegue hacia la nube.
-
Cloud: Toda la IA es casi privada y, por ende, se paga. Las nubes centralizan la forma en que se comunican los desarrolladores con los modelos de lenguaje, por lo tanto, profundizar en los servicios de la nube que componen tu solución es importante.
-
Testing: Existen distintos tipos de pruebas en los desarrollos, como pruebas unitarias, integración, etc. Hemos tenido que incorporar este tipo de pruebas aún cuando esto era lejano como científicos de datos. No sé si es un must, pero es un nice-to-have (tanto inglés jaja) dependiendo en qué estado de madurez esté tu equipo, la velocidad que su organización le este pidiendo, etc.
-
Colaborar: El colaborar creo que es un poco mía, no creo que haya tenido una iluminación, pero se me cuestionó en algún minuto que las personas pudiesen o deban tomar más de un proyecto. Creo que se puede, pero requiere harta planificación y definiciones o alcances claros. Este para mí es un must, pero uno bueno.
-
Clean Code y OOP: Nosotros desarrollamos en Python y normalmente el científico de datos vive en un jupyter notebook. Ahora debemos vivir dentro de .py que interactúan entre sí o realizan partes específicas de un flujo. Mientras más clean y mejor diseñado esté el código, más fácil es agregar funcionalidades nuevas y conectar distintas partes de un flujo. Clean code es casi un post aparte, quizás algún día escriba algo sobre lo que he ido aprendiendo en estos años.
Lo que aún falta
No es el post de la perfección y tampoco de lo bacán que soy o lo bueno que es mi equipo. (Lo es! Son secos.) Por lo tanto, suelo ser bien crítico de todo, incluyéndome a mí, entonces lo que falta te lo dejo a continuación.
En primer lugar, creo que testing no lo hemos explotado lo suficiente y mi impresión es que es necesario empezar a exigirlo dentro del equipo. En segundo lugar, en limpieza de código y reciclar las piezas de software, tenemos mucho que mejorar. Nuestros desarrollos se repiten, pero es poco lo que reciclamos y existe aún harto espacio de mejora ahí.
Por último, en FastAPI si bien hemos crecido y explotado su uso, aún falta. Pero, paso a paso y ladrillo a ladrillo, se construye la casa.
Lo último, creo que naturalmente esta área se transformará en un área de desarrollo tradicional con metodología ágil y eso involucra una célula completa de desarrollo y con la metodología aplicada al 100%. Aun cuando creo que este es el paso natural, debe ir acompañado de madurez tanto del equipo como la organización, sobre todo de la organización. Se debe entender que esta tecnología –finalmente– tiene una componente fuerte de desarrollo en los casos de uso puntuales o procedurales. (Sí, existe esa palabra jaja)
Gracias Totales
Hace harto tiempo quería escribir sobre esto. Dentro de mis reflexiones internas, pensaba incluso si es que este era un tema en sí mismo o era sujeto a escribir algo al respecto, pero la verdad es que en ese viaje interno de preguntas, si miro hace 1 año y medio atrás, los problemas que tenemos hoy como equipo son radicalmente distintos y, sin duda, son un tema interesantísimo a tratar.
En una conversación camino al metro con alguien cercano, la semana pasada, le comentaba que sentía que esto para mí era ingeniería en su más pura expresión, resolver un problema y convertirlo en algo real. Su reflexión es que la definición de ingeniería era simplificarle la vida a alguien, me encantó esto y quiero dejarlo registrado en estas últimas líneas para no olvidarlo. Efectivamente, le estamos haciendo la vida más fácil a las personas del banco.
Hasta la próxima.